
近期,夸克健康大模型成功通过中国12门核心学科的主任医师笔试评测,成为国内首个完成这一挑战的大模型。随后,夸克在 Github 和 arXiv 上发布了夸克健康大模型技术报告,公布了相关技术细节和训练策略,旨在为人工智能驱动的医疗咨询、诊断辅助和医疗搜索等应用提供坚实基础。
夸克健康大模型专为满足医疗领域复杂且高风险的需求而设计,通过精细处理的医疗数据、先进的检索增强生成(RAG)系统,以及大规模可验证的强化学习流程,满足用户的各类需求。
以下为模型技术实现细节,欢迎大家沟通交流。

在模型训练不同阶段,团队使用了三类核心医疗数据:医学资料、医学知识和医疗记录。这些数据为模型提供了及时的医学知识和详细的临床知识,也是大模型增强的核心数据。
医学资料:团队建立了一个全面的医学资料库,库中事实类知识覆盖率达到90%以上,概念类知识覆盖率达到84%,程序类知识覆盖率达到75%以上。这种从基础数据到复杂推理数据的递进式覆盖,与模型训练的不同阶段相契合。
医学知识:对于非结构化知识数据,团队基于特定方法的数据选择流程,将其用于持续预训练、指令微调、监督微调和强化学习等阶段。对于大语言模型(LLM)无法直接使用的结构化数据,团队使用知识转换技术将其转换为自然语言数据。

医疗数据源分类及规模
医疗记录:团队从两个接近实践的渠道中整理了一个大规模语料库。所有材料均经过严格的PHI移除流程,并将非结构化文本规范化分割成连贯的临床文档。

团队训练流程的初始阶段是指令微调(IFT),IFT致力于通过在庞大且多样化的指令-响应对数据集上对模型进行微调来弥合“对齐差距”。这一过程将模型从一个简单的文本补全引擎转变为一个能够理解和执行专业医疗任务的高效助手。
为此,团队遵循多任务提示训练原则,系统构建了一个面向任务的数据集,并采用双管齐下策略:一个基础的能力驱动框架和一个响应式的问题驱动增强循环。这种方法既确保了模型在广泛能力范围的覆盖,同时系统解决了已发现的模型缺陷。
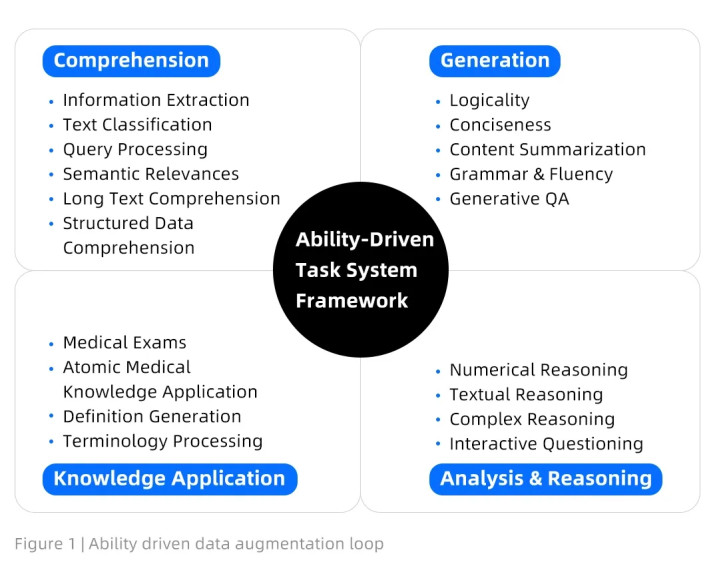
能力驱动框架
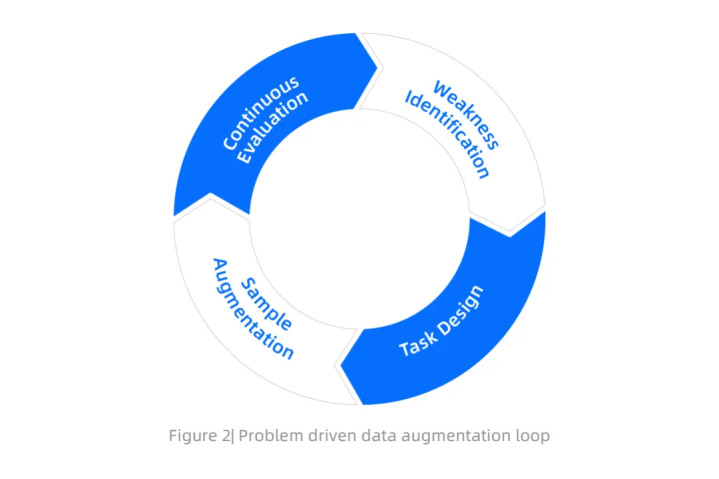
问题驱动增强循环
开发一个安全、准确且实用的医学大语言模型,关键在于监督微调(SFT)数据的质量。为此,团队设计了一套严谨的数据处理流程,以确保训练样本的多样性、稳健性以及医学合理性。
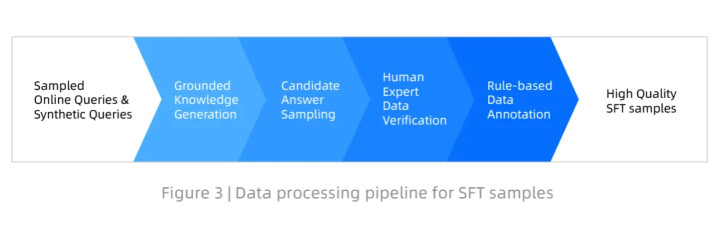
数据处理流程
经过严格训练,该模型能增强对错误或误导性信息的鲁棒性。它可以识别和抵抗各种形式的干扰,例如忽略不相关的参考资料、区分语义相似但不正确的医学概念,以及标记事实上不正确的信息。当用户查询时,模型能识别和处理包含错误前提、事实不一致或不合理假设的问题,防止生成不安全或荒谬的答案。

在大模型的多阶段训练方法中,还包括两个阶段的强化学习(RL),旨在培养模型的专门推理能力和通用一致性。
第一阶段强化学习:大规模医学强化学习
在医学领域方面,尤其是疾病诊断、合理用药和检验开具等核心任务,本质上均属于知识密集型,且高度依赖复杂的推理。为了显著提升大模型在这些复杂场景中的推理能力,团队进行了一个专门针对推理任务的强化学习(RL)阶段。
精准的奖励信号对于指导强化学习(RL)训练过程至关重要。对于具有明确基本事实(ground truth)的推理任务,团队设计了一个混合奖励模型封装在”验证器”中,该模型优先考虑规则,并通过模型进一步验证更广泛的事实。这种方法基于规则优先的原则,优先考虑来自既定医疗规则的客观且稳定的奖励信号,以防止奖励作弊。
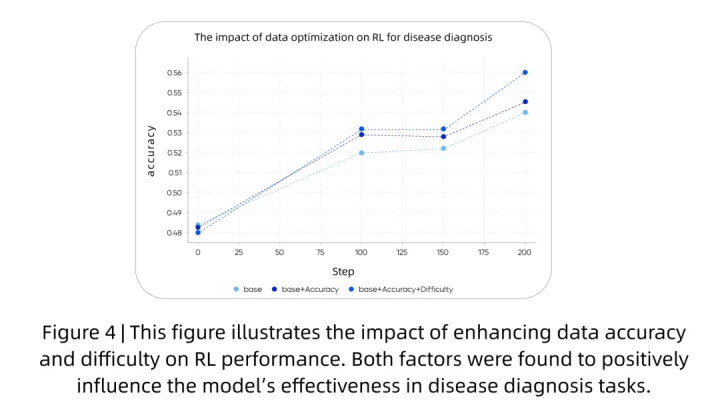
提高数据准确性和难度对强化学习(RL)性能有积极影响
第二阶段强化学习:通用强化学习集成
通用强化学习(RL)阶段的主要目标是利用强化学习(RL)来调整模型的行为,以使其符合人类的偏好和价值观。这个过程涉及开发一个奖励模型(RM),以定量评估模型输出的质量,并实施强化学习算法来优化基于策略的奖励信号。为了确保模型能够生成高质量的医疗响应,团队的RM会从三个核心维度评估模型输出:诚实性、有用性和内容合规性。
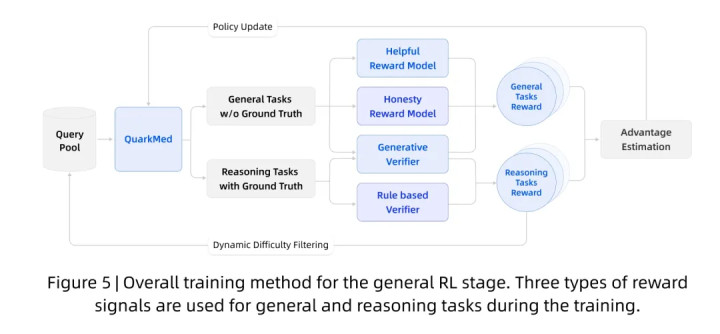
训练期间,针对一般任务和推理任务使用三种类型的奖励信号
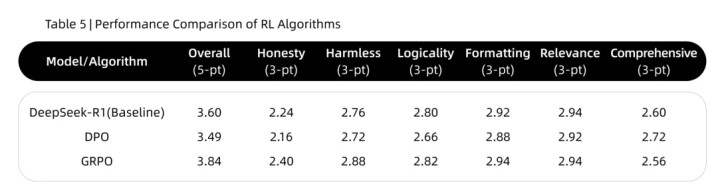
同时,团队对直接偏好优化(DPO)和群体相对策略优化(GRPO)进行了比较分析,用于评估它们的有效性。实验结果表明,GRPO在大多数维度上的表现显著优于 DPO。GRPO模型在总体得分、诚实和无害等关键维度上取得了最佳表现。因此,团队选择GRPO作为本项目的核心RL算法。

团队对夸克健康大模型在一系列公共(外部)和私有(内部)基准上进行了评估。它在同等规模模型中展现出了先进的性能,甚至与更大规模的专有模型相比也表现出了竞争力。
外部基准测试表现:与约 30B 参数类别中的其他领先开源模型相比,夸克健康大模型在各种医学问答和推理任务中表现出了更优异的性能。
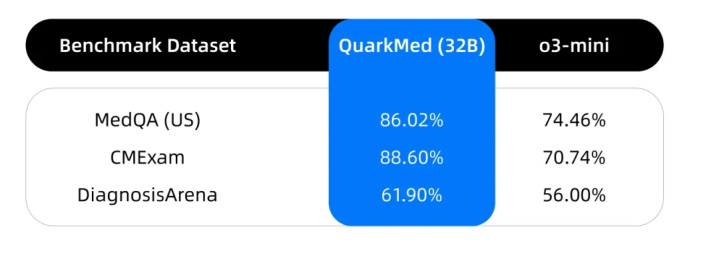
开放医疗基准部分测试结果
内部基准测试表现:中国医师资格考试(CPQExam)分为初级、中级、副高级、高级四个级别。在与通用模型对比中,夸克健康大模型呈现出考试难度越高、领先优势越明显的性能曲线。
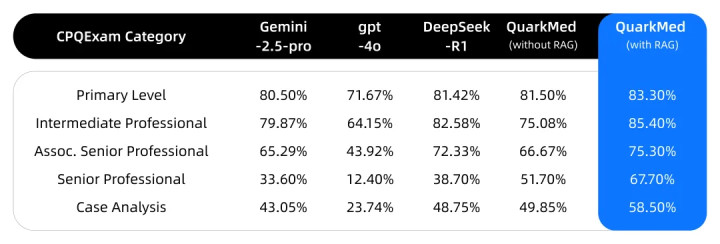
CPQExam测试结果

团队基于医学领域知识的多阶段训练方法,有效提升模型在医学推理任务上的表现,在开发可靠有效的医疗保健AI工具方面迈出重要一步。在发展过程中,医学知识的动态性和不断演变的特性也给团队带来了新的挑战。未来团队将集中在开发多模态能力上,构建一个更安全、更可靠的医学基础模型。
同时,团队计划发布基于中国医师资格考试(CPQExam)优化的内部基准测试集,以促进医学相关的 AI 研究,敬请期待。
欢迎查看完整报告,一起探讨交流!
